Chapter 12 線形モデル(t検定, 分散分析, 共分散分析)
前の章では、線形モデルの概要を見てきた。前の章で線形モデルを用いて行った分析は、要は「単回帰分析(一つの連続変量から、もう一方の連続変量の値を予測する分析)」であった。
この章では、線形モデルを用いて他の分析を行う。予測変数のパターンが異なるケースの演習を通して、線形モデルは正規分布を扱うあらゆるタイプの分析を内包したモデルであることを確認していく。
- 変数の標準化
- 予測変数がカテゴリの場合(ダミー変数)
- 予測変数がカテゴリの場合(複数のダミー変数)
- 交互作用
12.2 線形モデルに含まれる統計解析
線形モデルとは特定の解析を指すものではなく、正規分布を扱う様々な統計解析を包括的に扱う統計モデルである。例えば、変数の正規性を前提とするt検定や分散分析も線形モデルの中に含まれる。予測変数の種類や個数の違いによって、線形モデルは以下のそれぞれの統計解析と一致する。
| 分析 | 予測変数 | 予測変数の個数 |
|---|---|---|
| t検定 | 二値(0 or 1) | 1個 |
| 分散分析 | 二値 | 2個以上 |
| 共分散分析 | 二値及び連続量 | 二値が2個以上、連続量が1個以上 |
| 単回帰分析 | 連続量 | 1個 |
| 重回帰分析 | 連続量(二値を含んでも可) | 2個以上 |
前章では単回帰分析(予測変数が連続量で1個)を例として演習を行った。以下では、t検定や分散分析と似たことをlm()関数で行う練習を通して、予測変数がカテゴリーの場合の扱い方を学んでいく。
12.3 変数の標準化
解析の演習に入る前に、標準化(standardizing)について確認しておこう。標準化とは、元の値を「ゼロが平均値、1が標準偏差」と等しくなるように値を変換する処理のことをいう。変数を標準化しておくと、線形モデルの係数の解釈が直感的に理解しやすくなる事が多い。
例えば、前の章ではirisデータを使って単回帰分析を行った。
dat = iris #ここではirisを別の名前(dat)に変えて練習に用いる
result = lm(data = dat, Petal.Length ~ 1 + Sepal.Length)
summary(result)##
## Call:
## lm(formula = Petal.Length ~ 1 + Sepal.Length, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.47747 -0.59072 -0.00668 0.60484 2.49512
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -7.10144 0.50666 -14.02 <2e-16 ***
## Sepal.Length 1.85843 0.08586 21.65 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8678 on 148 degrees of freedom
## Multiple R-squared: 0.76, Adjusted R-squared: 0.7583
## F-statistic: 468.6 on 1 and 148 DF, p-value: < 2.2e-16切片の値はSepal.LengthがゼロのときのPetal.Lengthの予測値である。しかし、アヤメの花弁の長さがマイナスやゼロの値を取るというのはありえない。また、切片は予測変数がゼロのときの応答変数の値であるが、このデータも予測変数(すなわちがくの長さ)がゼロの場合も論理的には有り得ない。このように、元の値をそのまま使っても係数の解釈にこまる場面がある。
応答変数及び予測変数を標準化したものを使って同じ解析をして、結果を比較してみよう。具体的には、元の得点から平均値を引いて差の得点を求め、その差の得点を標準偏差で割る。
dat = dat |> dplyr::mutate(Petal.Length_std = (Petal.Length - mean(Petal.Length))/sd(Petal.Length),
Sepal.Length_std = (Sepal.Length - mean(Sepal.Length))/sd(Sepal.Length))
head(dat)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Petal.Length_std
## 1 5.1 3.5 1.4 0.2 setosa -1.335752
## 2 4.9 3.0 1.4 0.2 setosa -1.335752
## 3 4.7 3.2 1.3 0.2 setosa -1.392399
## 4 4.6 3.1 1.5 0.2 setosa -1.279104
## 5 5.0 3.6 1.4 0.2 setosa -1.335752
## 6 5.4 3.9 1.7 0.4 setosa -1.165809
## Sepal.Length_std
## 1 -0.8976739
## 2 -1.1392005
## 3 -1.3807271
## 4 -1.5014904
## 5 -1.0184372
## 6 -0.5353840標準化した得点を用いて線形モデルで解析を行う。
##
## Call:
## lm(formula = Petal.Length_std ~ 1 + Sepal.Length_std, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.40343 -0.33463 -0.00379 0.34263 1.41343
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.333e-16 4.014e-02 0.00 1
## Sepal.Length_std 8.718e-01 4.027e-02 21.65 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.4916 on 148 degrees of freedom
## Multiple R-squared: 0.76, Adjusted R-squared: 0.7583
## F-statistic: 468.6 on 1 and 148 DF, p-value: < 2.2e-16標準化しない得点を使ったときの解析結果と比べると、係数の値が変わっている。しかし、傾きのt値及びp値は変わっていない(標準化は単にデータを平行移動させただけなので、回帰直線の傾きは変わらない)。
切片は0、Sepal.Length_stdの効果は0.87である。切片の値は、Sepal.Length_stdがゼロのとき、つまりSepal.Lengthが平均値と等しいとき、Petal.Length_stdはほぼゼロの値を取る、つまりPetal.Lengthの平均値であることを意味している。また、Sepal.Length_stdの傾きは、Sepal.Length_stdが1のとき(つまりSepal.Lengthが1標準偏差分増加したとき)、Petal.Length_stdが0.87増えることを意味する。
このように、標準化することで算出された係数の解釈がしやすくなることが多い。以降の線形モデルを扱う分析の例でも、応答変数は標準化したものを用いる。
Rには標準化を行うための関数も用意されている。scale()を用いる。
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Petal.Length_std
## 1 5.1 3.5 1.4 0.2 setosa -1.335752
## 2 4.9 3.0 1.4 0.2 setosa -1.335752
## 3 4.7 3.2 1.3 0.2 setosa -1.392399
## 4 4.6 3.1 1.5 0.2 setosa -1.279104
## 5 5.0 3.6 1.4 0.2 setosa -1.335752
## 6 5.4 3.9 1.7 0.4 setosa -1.16580912.4 予測変数がカテゴリカル変数の場合(ダミー変数)
予測変数はカテゴリカル変数(質的変数)でも構わない。ただし、予測変数を0か1のどちらかの値を取るダミー変数(dummy variable)に変換する必要がある。
Rに入っているsleepデータを少し変えたもの使って、カテゴリカル変数を予測変数に含む線形モデルの解析をしてみよう。
sleep_1 = sleep |> dplyr::select(-ID) |>
dplyr::mutate(group = ifelse(group == 1, "control", "treatment"))
sleep_1## extra group
## 1 0.7 control
## 2 -1.6 control
## 3 -0.2 control
## 4 -1.2 control
## 5 -0.1 control
## 6 3.4 control
## 7 3.7 control
## 8 0.8 control
## 9 0.0 control
## 10 2.0 control
## 11 1.9 treatment
## 12 0.8 treatment
## 13 1.1 treatment
## 14 0.1 treatment
## 15 -0.1 treatment
## 16 4.4 treatment
## 17 5.5 treatment
## 18 1.6 treatment
## 19 4.6 treatment
## 20 3.4 treatmentgroupはグループを意味する変数である(統制群controlもしくは実験群treatment)。まずこれを、「treatmentなら1、controlなら0」とする新たな変数dgroupを作る。
## extra group dgroup
## 1 0.7 control 0
## 2 -1.6 control 0
## 3 -0.2 control 0
## 4 -1.2 control 0
## 5 -0.1 control 0
## 6 3.4 control 0
## 7 3.7 control 0
## 8 0.8 control 0
## 9 0.0 control 0
## 10 2.0 control 0
## 11 1.9 treatment 1
## 12 0.8 treatment 1
## 13 1.1 treatment 1
## 14 0.1 treatment 1
## 15 -0.1 treatment 1
## 16 4.4 treatment 1
## 17 5.5 treatment 1
## 18 1.6 treatment 1
## 19 4.6 treatment 1
## 20 3.4 treatment 1ifelse()関数は、ifelse(XXX, A, B)と表記することで、「XXXの条件に当てはまればA、当てはまらなければB」という処理をしてくれる。ここでは、変数groupについて、treatmentならば1, それ以外なら0に変換し、0か1を取る変数dgroupを新たに作った。
このdgroupがダミー変数である。
解析に用いるモデルを確認すると、以下のようになる。
\[ \begin{equation} \hat{y} = \alpha + \beta dgroup \\ \tag{1}\\ y \sim \text{Normal}(\hat{y}, \sigma) \end{equation} \]
\(dgroup\)は0か1のどちらかを取る変数で、\(dgroup = 0\)のとき、つまり統制群のとき、応答変数の予測値は\(\mu = \alpha\)となる。\(dgroup = 1\)のとき、つまり実験群のとき、応答変数の予測値は\(\mu = \alpha + \beta\)となる。すなわち、切片\(\alpha\)は統制群のときの効果、傾き\(\beta\)は実験群の時に加わる実験群特有の効果を意味する。
lm()を使って、上のモデル式のパラメータの推定をしよう。
sleep_1 = sleep_1 |> dplyr::mutate(extra_std = scale(extra)) #応答変数を標準化したものを用いる
result = lm(data = sleep_1, extra_std ~ 1 + dgroup)
summary(result)##
## Call:
## lm(formula = extra_std ~ 1 + dgroup, data = sleep_1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.2042 -0.6467 -0.2874 0.7210 1.5709
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.3915 0.2975 -1.316 0.2048
## dgroup 0.7830 0.4208 1.861 0.0792 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.9409 on 18 degrees of freedom
## Multiple R-squared: 0.1613, Adjusted R-squared: 0.1147
## F-statistic: 3.463 on 1 and 18 DF, p-value: 0.079192つの群間で平均値を比較するときにはt検定がよく使われる。t.test()関数を使って\(dgroup=0\)と\(dgroup=1\)との間で\(y\)の値の平均値を比較したときのt値及びp値の結果が、lm()の傾きのt値及びp値と一致することを確認しよう。
##
## Welch Two Sample t-test
##
## data: extra_std by dgroup
## t = -1.8608, df = 17.776, p-value = 0.07939
## alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
## 95 percent confidence interval:
## -1.6677984 0.1018292
## sample estimates:
## mean in group 0 mean in group 1
## -0.3914923 0.3914923lm()の傾きの検定は、「傾きがゼロである」という帰無仮説を検定している。傾きの係数が意味することは、予測変数\(dgroup\)が1単位増えたときの応答変数\(y\)の変化量であった。傾きの検定は、「\(dgroup=0\) から \(dgroup=1\) に変化することによって、 応答変数(extra) が上昇(下降)するか(傾きがゼロではないか)」を検定している。要は、「\(dgroup=0\)と\(dgroup=1\)の間で\(y\)の値に差があるか」を検定しているのと論理的に同じである。
このように、予測変数が1つで、予測変数が二値(0もしくは1)であるときの線形モデルは、t検定に対応する。
12.5 グループが複数ある場合(一要因の分散分析)
先ほどの例は、統制群と実験群の二つのグループの場合であった。例えば実験で統制群、実験群1、実験群2といったように三つ以上のグループを設定した場合は、どうダミー変数を作成すればよいのか?
Rに入っているPlantGrowthを例として見ていこう。以下のプログラムを実行して、データを作ろう。
dat = PlantGrowth |>
dplyr::mutate(t1 = ifelse(group == "trt1", 1, 0),
t2 = ifelse(group == "trt2", 1, 0)
)
dat## weight group t1 t2
## 1 4.17 ctrl 0 0
## 2 5.58 ctrl 0 0
## 3 5.18 ctrl 0 0
## 4 6.11 ctrl 0 0
## 5 4.50 ctrl 0 0
## 6 4.61 ctrl 0 0
## 7 5.17 ctrl 0 0
## 8 4.53 ctrl 0 0
## 9 5.33 ctrl 0 0
## 10 5.14 ctrl 0 0
## 11 4.81 trt1 1 0
## 12 4.17 trt1 1 0
## 13 4.41 trt1 1 0
## 14 3.59 trt1 1 0
## 15 5.87 trt1 1 0
## 16 3.83 trt1 1 0
## 17 6.03 trt1 1 0
## 18 4.89 trt1 1 0
## 19 4.32 trt1 1 0
## 20 4.69 trt1 1 0
## 21 6.31 trt2 0 1
## 22 5.12 trt2 0 1
## 23 5.54 trt2 0 1
## 24 5.50 trt2 0 1
## 25 5.37 trt2 0 1
## 26 5.29 trt2 0 1
## 27 4.92 trt2 0 1
## 28 6.15 trt2 0 1
## 29 5.80 trt2 0 1
## 30 5.26 trt2 0 1ダミー変数を2つ作成した。ctrlのときは「t1 = 0, t2 = 0」,trt1のときは「t1 = 1, t2 = 0」,trt2のときは「t1 = 0, t2 = 1」となっている。これら2つのダミー変数を線形予測子に加えたモデルは、モデルは以下のようになる。
\[
\begin{equation}
\hat{y} = \alpha + \beta_{t1} t_1 + \beta_{t2} t_2 \\ \tag{3}
y \sim \text{Normal}(\hat{y}, \sigma)
\end{equation}
\]
切片\(\alpha\)は「t1 = 0, t2 = 0(すなわち、ctrlのとき)」の\(\hat{y}\)の値と等しい。
傾き\(\beta_{t1}\)は「t1 = 1, t2 = 0(すなわち、trt1のとき)」の\(\hat{y}\)の値と等しい。
傾き\(\beta_{t2}\)は「t1 = 0, t2 = 1(すなわち、trt2のとき)」の\(\hat{y}\)の値と等しい。
このように、グループの数が\(K\)個ある場合には、ダミー変数を\(K-1\)個作れば全てのグループの予測値\(\hat{y}\)を線形予測子で表すことができる。
lm()で傾き及び切片のパラメータを推定しよう。
dat = dat |> dplyr::mutate(weight_std = scale(weight)) #応答変数を標準化したものを用いる
result = lm(data = dat, weight_std ~ t1 + t2 + 1)
summary(result)##
## Call:
## lm(formula = weight_std ~ t1 + t2 + 1, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.52740 -0.59613 -0.00856 0.37472 1.95239
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.05847 0.28113 -0.208 0.8368
## t1 -0.52910 0.39758 -1.331 0.1944
## t2 0.70451 0.39758 1.772 0.0877 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.889 on 27 degrees of freedom
## Multiple R-squared: 0.2641, Adjusted R-squared: 0.2096
## F-statistic: 4.846 on 2 and 27 DF, p-value: 0.01591式(3)より、切片の推定値は\(t_1=0\)かつ\(t_2=0\)のときの\(\mu\)、つまり統制群(ctrl)のときの応答変数weight_stdの推定値を意味している。各ダミー変数の係数(傾き)は、切片に加わる各条件の効果を意味している。例えば、t2の係数は0.7であるが、これは\(t_2\)のとき(つまりtrt2のとき)の応答変数の予測値は、 0.65(= 切片 + t2の傾き)となることを示している。
係数の意味することは、基準となるグループ(どのダミー変数も0となるグループ)と比べての効果ということになる。
図でも条件別にweight_stdの分布を確認してみよう。分布を見ても同様の傾向があるが、線形モデルの解析の結果その効果が有意であることが確認できた。
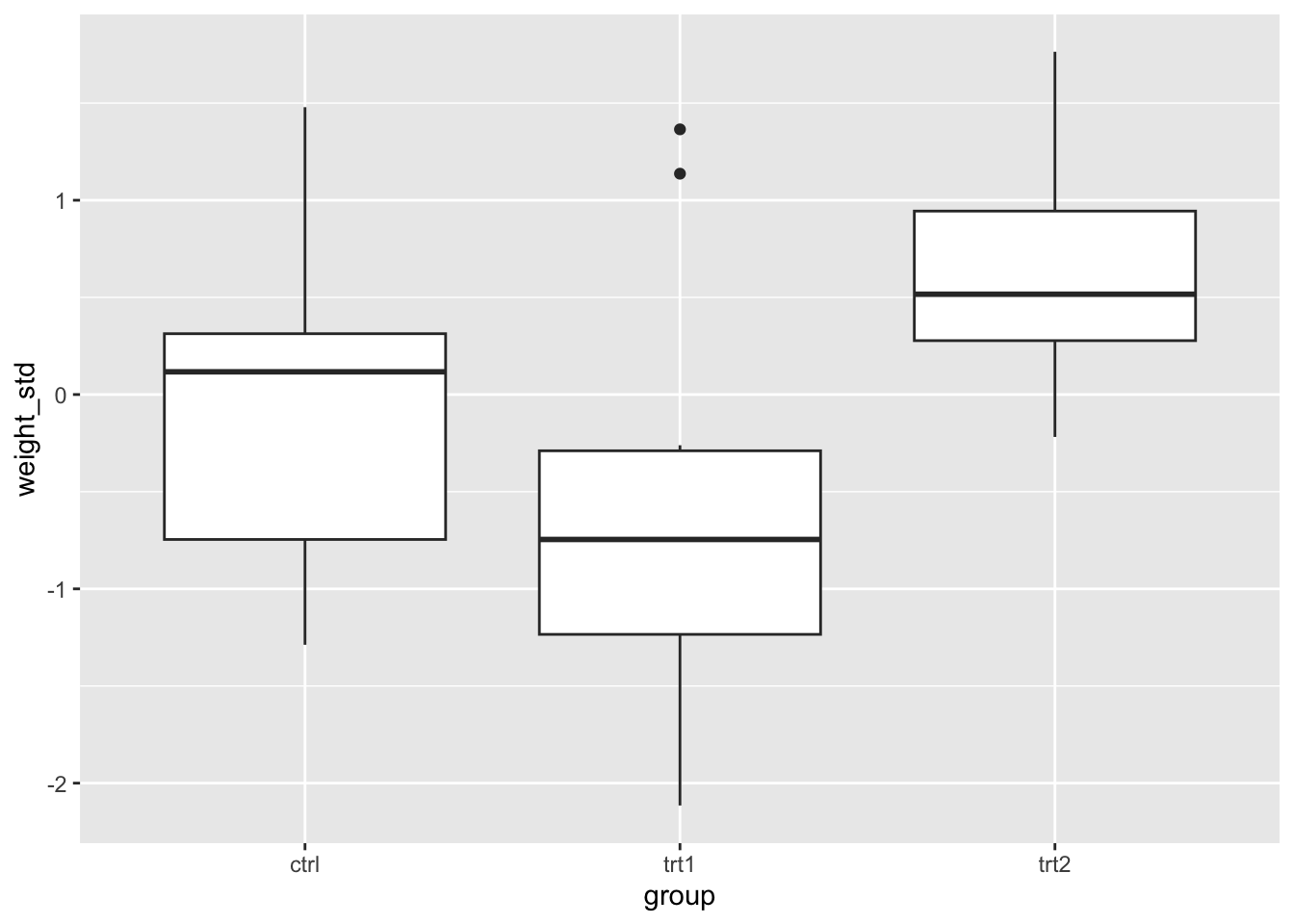
モデル(式)を確認しながら、係数が何を意味しているのかを常に意識するようにしよう。
このテキストでは練習のためにダミー変数を自分でプログラムを書いて作っているが、lm()関数にカテゴリカル変数をそのまま入れても結果を出力してくれる。カテゴリのうちアルファベット順で最初に出てくるカテゴリ(以下のPlantGrowthの例ではctrl)を基準として、残りのダミー変数を自動で作ってくれている。
dat = PlantGrowth |> dplyr::mutate(weight_std = scale(weight)) #応答変数を標準化したものを用いる
result = lm(data = dat, weight_std ~ group)
summary(result)##
## Call:
## lm(formula = weight_std ~ group, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.52740 -0.59613 -0.00856 0.37472 1.95239
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.05847 0.28113 -0.208 0.8368
## grouptrt1 -0.52910 0.39758 -1.331 0.1944
## grouptrt2 0.70451 0.39758 1.772 0.0877 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.889 on 27 degrees of freedom
## Multiple R-squared: 0.2641, Adjusted R-squared: 0.2096
## F-statistic: 4.846 on 2 and 27 DF, p-value: 0.0159112.6 交互作用(2要因の分散分析)
次は、線形モデルで交互作用を扱う方法について確認する。2要因以上の分散分析と同様のことを線形モデルで行う。
以下のプログラムを実行して、サンプルデータdを作ろう。
set.seed(1)
x = round(runif(n = 20, min = 1, max = 10),0)
mu = 0.1 + 0.4 * x
y = rnorm(n = 20, mean = mu, sd = 1)
d_M = data.frame(x = x, y = y, gender = "M")
x = round(runif(n = 20, min = 1, max = 10),0)
mu = 0.3 + -0.6 * x
y = rnorm(n = 20, mean = mu, sd = 1)
d_F = data.frame(x = x, y = y, gender = "F")
d = rbind(d_M, d_F)
head(d)## x y gender
## 1 3 2.811781 M
## 2 4 2.089843 M
## 3 6 1.878759 M
## 4 9 1.485300 M
## 5 3 2.424931 M
## 6 9 3.655066 Mこのデータdには、x, y, genderの3つの変数が含まれている。genderは性別を意味する変数とする。M(男性)かF(女性)のいずれかである。男女別に、実験で2つの変数を測定したとしよう。
応答変数をy、予測変数をxとして線形モデルで切片及びxの傾きのパラメータを推定する。モデルは以下のようになる。
\[ \begin{equation} \hat{y} = \alpha + \beta x \\ \tag{4} y \sim \text{Normal}(\hat{y}, \sigma) \end{equation} \]
lm()関数を使って推定しよう(\(x\)と\(y\)の散布図及び係数の信頼区間も図示する)。
##
## Call:
## lm(formula = y ~ 1 + x, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.8209 -2.5577 -0.7021 2.4363 5.1560
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.7389 1.3472 0.549 0.587
## x -0.1811 0.2060 -0.879 0.385
##
## Residual standard error: 3.231 on 38 degrees of freedom
## Multiple R-squared: 0.01993, Adjusted R-squared: -0.005863
## F-statistic: 0.7727 on 1 and 38 DF, p-value: 0.3849newdat = data.frame(x = seq(1,10,0.1))
result_conf = predict(result, new = newdat, interval = "confidence", level = 0.95)
plot_conf = data.frame(x = seq(1,10,0.1), result_conf)
ggplot2::ggplot() +
ggplot2::geom_point(data = d, aes(x = x, y = y), size = 3) +
ggplot2::geom_line(data = plot_conf, aes(x = x, y = fit)) +
ggplot2::geom_ribbon(data = plot_conf, aes(x = x, ymax = upr, ymin = lwr), alpha = 0.4) 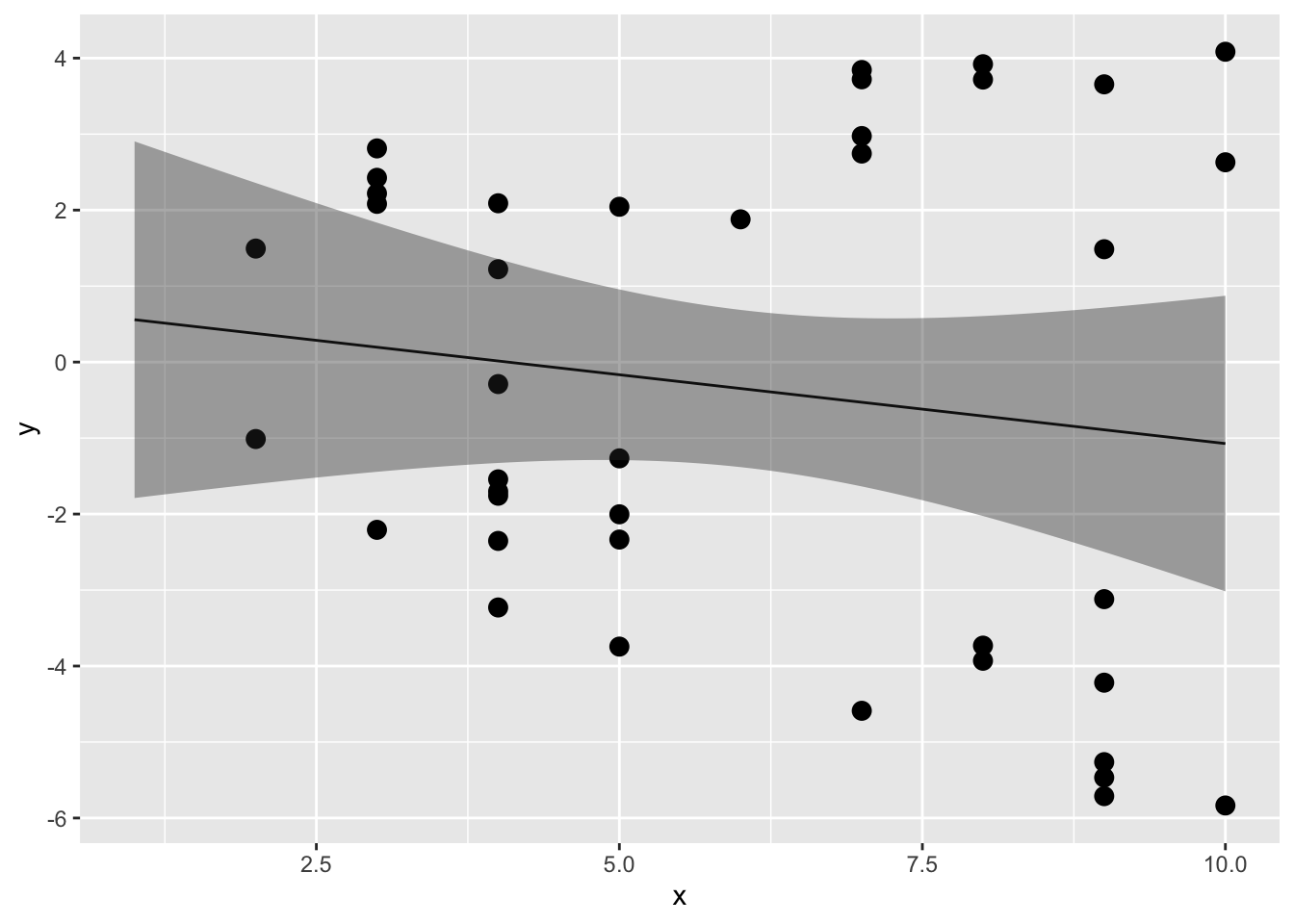
予測変数xの傾きはほぼフラットで、yに対してあまり効果がないようにみえる。
しかし、このデータdにはもう一つ性別を意味するgenderという変数が含まれていた。genderを区別して、またxとyの散布図を見てみよう。
ggplot2::ggplot() +
ggplot2::geom_point(data = d, aes(x = x, y = y, shape = gender, color=gender), size = 3) 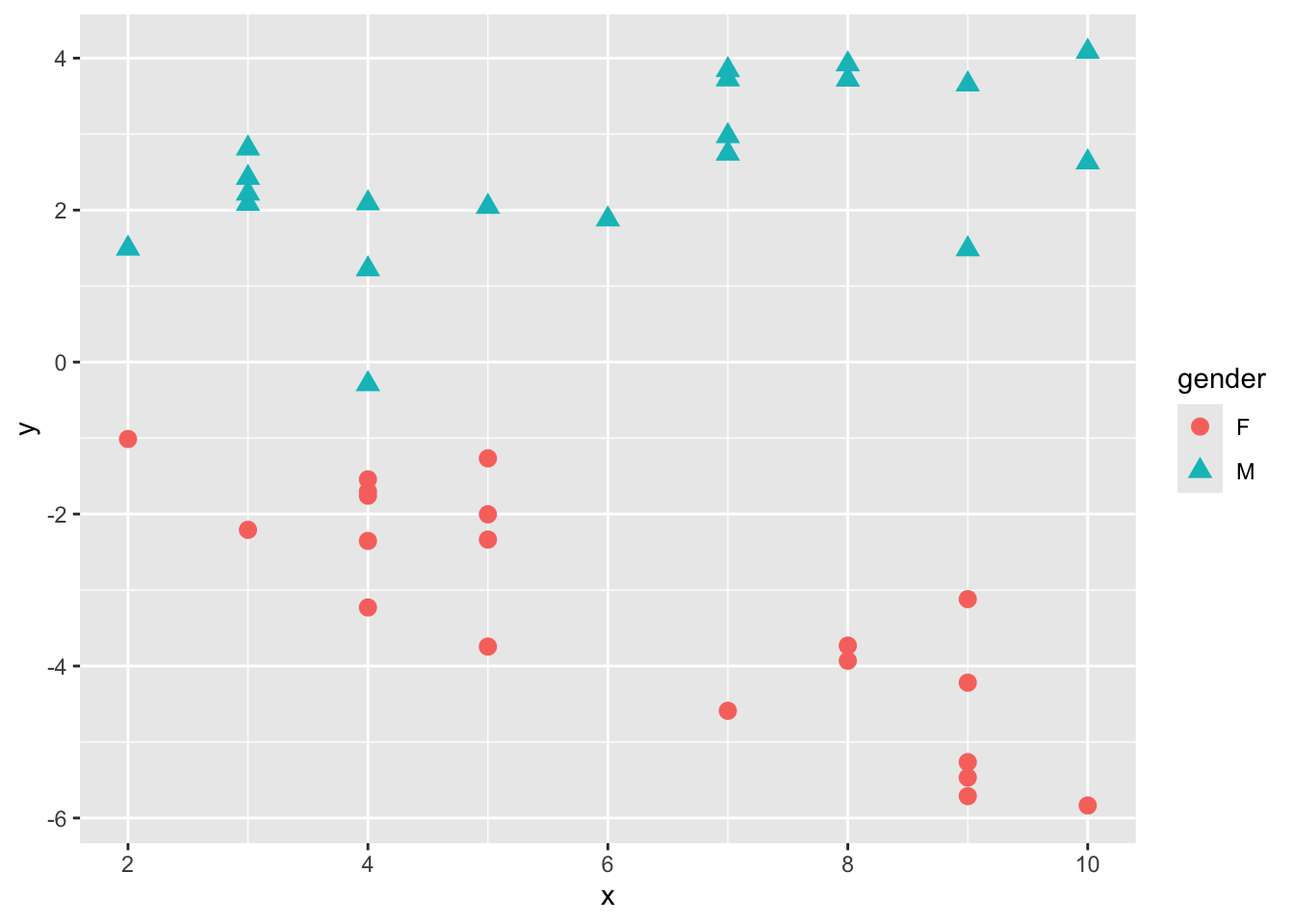
性別が女性(F)か男性(M)かで、xとyの関係が違うようである。
このように、別の変数との組み合わせにより、変数間の関係が変化することを交互作用(interaction)という。このデータでも、応答変数yに対して性別genderとxの交互作用がありそうである。
交互作用のあるモデルは、以下のように表現する。
\[ \begin{equation} \hat{y} = \alpha + \beta_{1} x + \beta_{2} M + \beta_{3} xM \\ \tag{5} y \sim \text{Normal}(\hat{y}, \sigma) \end{equation} \]
\(M\)は性別genderのダミー変数で、M(男性)ならば1、F(女性)ならば0の変数とする。
線形モデルでは、交互作用は予測変数同士の積で扱う。式5の線形予測子を\(x\)で整理すると、
\[ \begin{equation} \hat{y} = \alpha +(\beta_{1} + \beta_{3}M) x +\beta_{2}M \\ \tag{6} \end{equation} \] となる。つまり、男性の場合には式6に\(M=1\)を代入すると、
\[ \begin{equation} \hat{y} = \alpha +(\beta_{1} + \beta_{3}) x +\beta_{2} \end{equation} \]
となるので、男性の時の\(x\)の効果は、\(x\)に係る傾き\(\beta_{1}\)と\(x\)と\(M\)の積に係る傾き\(\beta_{3}\)をあわせたものになる。
一方、女性の場合には、式6にM=0を代入すると
\[ \begin{equation} \hat{y} = \alpha + \beta_{1} x \\ \end{equation} \]
となる。つまり、\(x\)に係る傾きである\(\beta_{1}\)が女性の時の\(x\)の効果を意味する。
言い換えると、交互作用項にかかる傾き\(\beta_{3}\)は、男性のときに女性の\(x\)の効果に追加分でかかる\(x\)の傾きの変化量を意味することになる。
このように、交互作用を考慮する予測変数の積をモデルに加えることで、男性か女性かで切片及び傾きが変化することを表現できる。
d$M = ifelse(d$gender == "M", 1, 0) #genderがMならば1, Fならば1のダミー変数を作る
result = lm(data = d, y ~ 1 + x*M)
summary(result)##
## Call:
## lm(formula = y ~ 1 + x * M, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.3555 -0.6534 0.2205 0.5636 1.6618
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.05079 0.53625 0.095 0.925
## x -0.53691 0.08107 -6.622 1.03e-07 ***
## M 1.04827 0.73745 1.421 0.164
## x:M 0.77868 0.11274 6.907 4.35e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8827 on 36 degrees of freedom
## Multiple R-squared: 0.9307, Adjusted R-squared: 0.9249
## F-statistic: 161.1 on 3 and 36 DF, p-value: < 2.2e-162つの予測変数の積の傾き(\(\beta_{3}\))は、x:Mである。p値も小さく、有意な効果を持っているようである。
サンプルデータについて、推定されたパラメータを元に、男女別に線形モデルの直線の信頼区間を図示したのが以下の図である。
new_x = seq(1,10,0.1)
newdat = data.frame(x = rep(new_x,2), M = c(rep(0,length(new_x)), rep(1,length(new_x))))
result_conf = predict(result, new = newdat, interval = "confidence", level = 0.95)
plot_conf = data.frame(newdat, result_conf)
plot_conf$gender = ifelse(plot_conf$M == 1, "M", "F")
ggplot2::ggplot() +
ggplot2::geom_point(data = d, aes(x = x, y = y, shape = gender, color=gender), size = 3) +
ggplot2::geom_line(data = plot_conf, aes(x = x, y = fit, color=gender)) +
ggplot2::geom_ribbon(data = plot_conf, aes(x = x, ymax = upr, ymin = lwr, color =gender), alpha = 0.4) 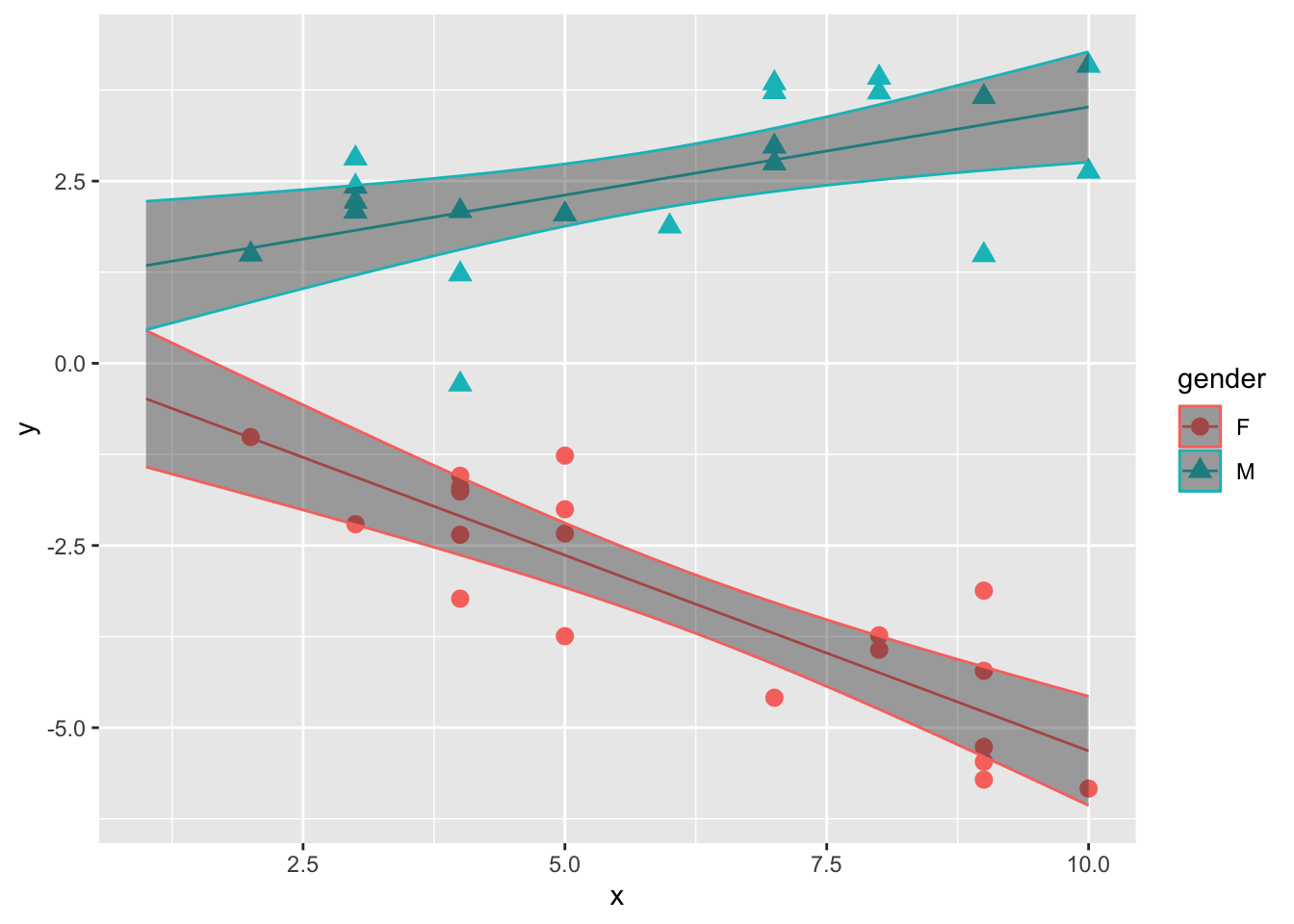
12.6.1 交互作用を扱うモデルの解釈
2要因以上の分散分析と同様に、線形モデルでも交互作用の有無を検討することができる。しかし、ここで注意が必要なのは、交互作用を含む線形モデルは解釈が複雑になることである。
分散分析では、変数の組み合わせの効果である交互作用とは別に、その変数そのものの効果である主効果についての検定も行われる。では、上述の線形モデルの\(\beta_{1}\)及び\(\beta_{2}\)のパラメータはそれぞれ、性別\(M\)及び予測変数\(x\)の主効果として解釈できるのだろうか?
もう一度、式5の線形予測子を見てみよう。
\[ \hat{y} = \alpha + \beta_{1} x + \beta_{2} M + \beta_{3} xM \\ \tag{5} \]
\(M = 0\)を代入すると、\(\hat{y} = \alpha +\beta_{1} x\)となる。\(M = 0\)はつまり女性であることを意味するので、\(\beta_{1}\)は「データが女性であるときの、予測変数\(x\)が1単位増加したときの応答変数\(y\)の変化量」を意味する。 つまり、交互作用項を含む際のある予測変数の傾きは、他の予測変数がゼロであるときの予測変数の効果を意味している。すなわち、\(x\)の傾き\(\beta_{1}\)は「限定的な条件のもとでの予測変数の応答変数に対する効果」を示しており、主効果の一般的理解である「応答変数に対する予測変数の平均的効果」とは異なる。
このように、交互作用を含むモデルの場合、予測変数の傾きは必ずしも主効果を意味するわけではない。次の節の補足で、この問題に対する対処法について説明する。
予測変数(ダミー変数も含む)を標準化した場合には、各予測変数の傾きの解釈の仕方も変わってくる。
#データを再度作成する。
set.seed(1)
x = round(runif(n = 20, min = 1, max = 10),0)
mu = 0.1 + 0.4 * x
y = rnorm(n = 20, mean = mu, sd = 1)
d_M = data.frame(x = x, y = y, gender = "M")
x = round(runif(n = 20, min = 1, max = 10),0)
mu = 0.3 + -0.6 * x
y = rnorm(n = 20, mean = mu, sd = 1)
d_F = data.frame(x = x, y = y, gender = "F")
d = rbind(d_M, d_F)
d$M = ifelse(d$gender == "M", 1, 0) #genderがMならば1, Fならば1のダミー変数を作る##
## Call:
## lm(formula = y ~ 1 + x * M, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.3555 -0.6534 0.2205 0.5636 1.6618
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.05079 0.53625 0.095 0.925
## x -0.53691 0.08107 -6.622 1.03e-07 ***
## M 1.04827 0.73745 1.421 0.164
## x:M 0.77868 0.11274 6.907 4.35e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8827 on 36 degrees of freedom
## Multiple R-squared: 0.9307, Adjusted R-squared: 0.9249
## F-statistic: 161.1 on 3 and 36 DF, p-value: < 2.2e-16応答変数と予測変数を標準化する。ダミー変数も標準化する。
## x y gender M y_std x_std M_std
## 1 3 2.811781 M 1 0.9835716 -1.21465482 0.9874209
## 2 4 2.089843 M 1 0.7594727 -0.81640734 0.9874209
## 3 6 1.878759 M 1 0.6939495 -0.01991237 0.9874209
## 4 9 1.485300 M 1 0.5718146 1.17483007 0.9874209
## 5 3 2.424931 M 1 0.8634883 -1.21465482 0.9874209
## 6 9 3.655066 M 1 1.2453383 1.17483007 0.9874209##
## Call:
## lm(formula = y_std ~ 1 + x_std * M_std, data = d)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.73117 -0.20282 0.06843 0.17496 0.51584
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.01209 0.04336 0.279 0.7821
## x_std -0.11502 0.04394 -2.618 0.0129 *
## M_std 0.90526 0.04391 20.615 < 2e-16 ***
## x_std:M_std 0.30734 0.04450 6.907 4.35e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.274 on 36 degrees of freedom
## Multiple R-squared: 0.9307, Adjusted R-squared: 0.9249
## F-statistic: 161.1 on 3 and 36 DF, p-value: < 2.2e-16それぞれの係数とp値が変わった。
変数を標準化する前のモデルでは、パラメータ\(\beta_{1}\)は「女性のときのxの傾き」であり、特定のカテゴリのときの予測変数xが応答変数に及ぼす影響を意味していた。
これに対し、標準化した後のモデルではx_stdの傾きが意味することは、「他の変数がゼロのとき、つまり平均であるときに、x_stdが1単位(1標準偏差)変化したときの応答変数の変化量」を意味することになる。他の変数が特定の条件である場合ではなく、平均的水準であるときの予測変数の効果に関心がある場合は標準化した変数を用いるとよい。
12.7 予測変数が複数ある場合(共分散分析または重回帰分析)
予測変数は連続量もカテゴリカル変数でも何でも含めても良い。
12.7.1 変数の効果の統制
予測変数を複数加えた線形モデルの解析のメリットは、ある予測変数について他の予測変数の効果を統制(control)したときの効果を検討できることにある。
Rで標準で入っているattitudeデータを使って、予測変数が複数ある場合の線形モデルの解析の結果を確認してみよう。
## rating complaints privileges learning raises critical advance
## 1 43 51 30 39 61 92 45
## 2 63 64 51 54 63 73 47
## 3 71 70 68 69 76 86 48
## 4 61 63 45 47 54 84 35
## 5 81 78 56 66 71 83 47
## 6 43 55 49 44 54 49 34以下のように、complaints, privileges, learning, raisesの4つを予測変数として、ratingの値の推定を行ってみよう。
dat = attitude |> dplyr::mutate(rating_std = scale(rating),
complaints_std = scale(complaints),
privileges_std = scale(privileges),
learning_std = scale(learning),
raises_std = scale(raises)
) #変数を標準化したものを使う
result = lm(data = dat, rating_std ~ 1 + complaints_std + privileges_std + learning_std + raises_std)
summary(result)##
## Call:
## lm(formula = rating_std ~ 1 + complaints_std + privileges_std +
## learning_std + raises_std, data = dat)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.9255 -0.4433 0.0492 0.4765 0.9231
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.056e-15 1.049e-01 0.000 1.000
## complaints_std 7.560e-01 1.593e-01 4.745 7.21e-05 ***
## privileges_std -1.034e-01 1.326e-01 -0.780 0.443
## learning_std 2.375e-01 1.488e-01 1.596 0.123
## raises_std -2.179e-02 1.571e-01 -0.139 0.891
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5748 on 25 degrees of freedom
## Multiple R-squared: 0.7152, Adjusted R-squared: 0.6697
## F-statistic: 15.7 on 4 and 25 DF, p-value: 1.509e-06切片(Intercept)は全ての予測変数の値がゼロ(ここでは標準化しているので平均)のときの応答変数の予測値である。
各予測変数の傾きの値は「他の変数の影響を統制したときの、その予測変数が1単位変化したときの応答変数量の変化量」を意味する。例えば、complaintsの係数0.76は、その他の予測変数privileges, learning, raisesの値が一定だと仮定したときの、complaintsがratingに与える効果を示す。言い換えれば、モデルに含まれる他の予測変数の値に関係なく、complaintsが独立にratingに与える効果を意味する。
複数の予測変数を入れることで、他の予測変数の影響を統制した上での予測変数が応答変数に及ぼす影響を検討することができる。
12.8 まとめ
この章では、予測変数がカテゴリカル変数の場合及び交互作用を含むモデルの場合を学んできた。
- 予測変数がカテゴリカル変数の場合は、0か1の値を取るダミー変数にして線形予測子に投入する。
- 3つ以上のカテゴリの場合は、カテゴリの数-1個分のダミー変数を線形予測子に投入する。
- 2つの予測変数の組み合わせの効果(交互作用)を見たい場合は、2つの予測変数の積を線形予測子に投入する。
- 予測変数を複数加えたときの各予測変数の傾きは、他の予測変数の影響を統制した上での、その予測変数の応答変数に及ぼす効果を意味する。
線形予測子を拡張することで、正規分布を扱う様々な統計解析を線形モデルを扱う関数(lm)のみで行うことができることを学んできた。
この章では、応答変数は正規分布に従うという前提をおいてきたが、応答変数が従う確率分布を正規分布以外にすることも可能である。以降の章では、応答変数が従う確率分布を変更して一般化した「一般化線形モデル」を扱っていく。
12.9 確認問題
問1
Rで標準で入っているデータwarpbreaksを使って練習をする。
## breaks wool tension
## 1 26 A L
## 2 30 A L
## 3 54 A L
## 4 25 A L
## 5 70 A L
## 6 52 A L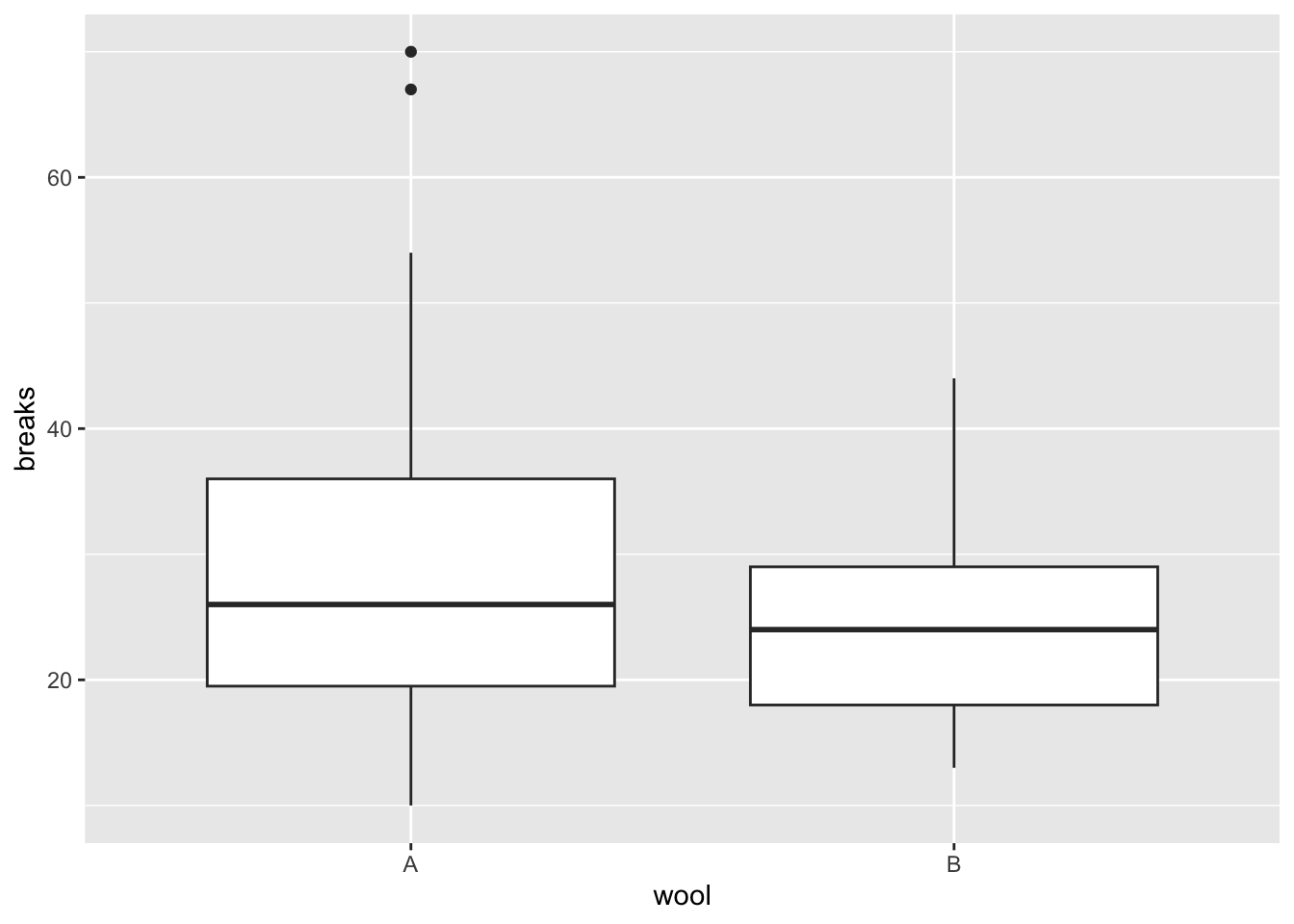
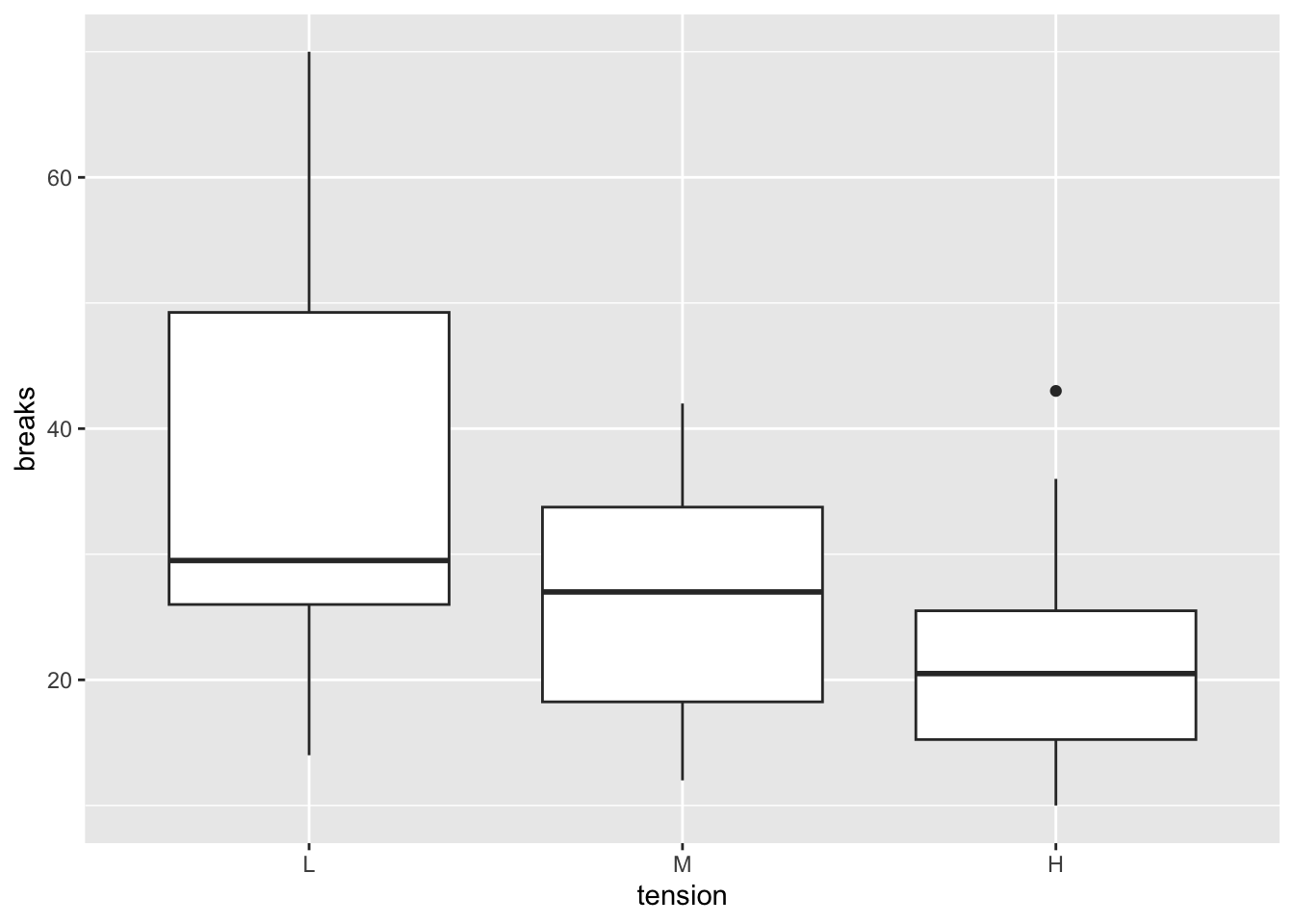
問2
問1に引き続き、Rで標準で入っているデータwarpbreaksを使って練習をする。ただし、tensionがHの部分を除いたデータを用いる。
## breaks wool tension
## 1 26 A L
## 2 30 A L
## 3 54 A L
## 4 25 A L
## 5 70 A L
## 6 52 A Lggplot2::ggplot() +
ggplot2::geom_boxplot(data = prac_dat_2, aes(x = wool, y = breaks, fill = tension))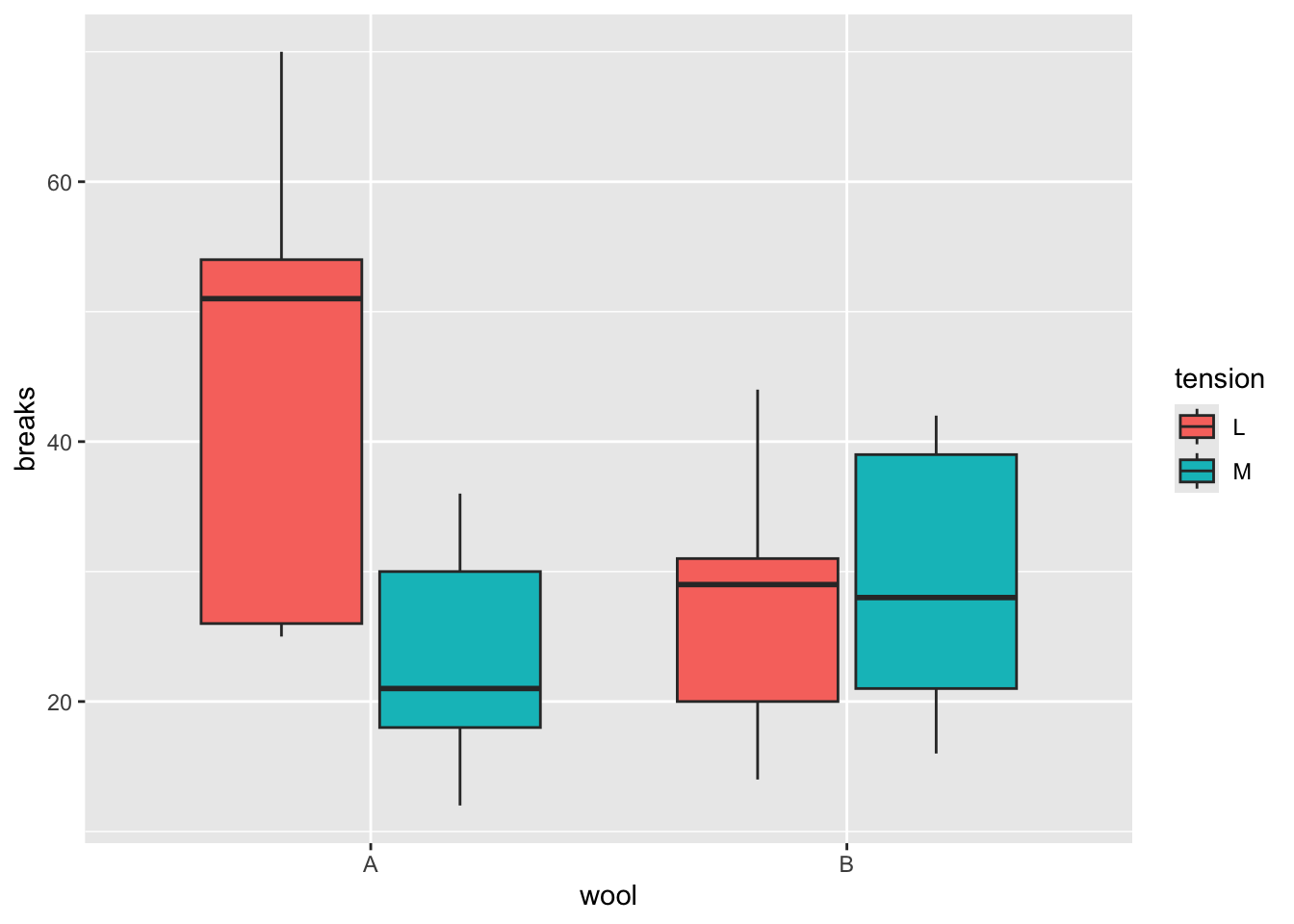
breaksを応答変数、wool, tension, wool及びtensionの交互作用項を予測変数とした線形モデルを行い、切片、woolの傾き、tensionの傾き、交互作用項の推定値を報告せよ。
12.10 補足1(emmeans)
この章では、ダミー変数を複数加えたモデル及び交互作用を加えたモデルで一要因の分散分析や二要因の分散分析と同様のことができることを学んできた。ただし、分散分析では条件の効果が有意だった場合には、どの条件間で差があるかを多重比較補正をした上で比較するプロセスが必要となる。
ここでは、emmeansパッケージを用いてlm()関数で多重比較補正を行う手順を紹介する(詳細はemmeansパッケージのヘルプを参照のこと)。
12.10.1 一要因の分散分析における多重比較
dat = PlantGrowth |> dplyr::mutate(weight_std = scale(weight))
result = lm(data = dat, weight_std ~ group)
emm = emmeans::emmeans(result, ~ group) #モデルから推定された各カテゴリのmarginal mean(emmeans)を算出する
emm## group emmean SE df lower.CL upper.CL
## ctrl -0.0585 0.281 27 -0.6353 0.5184
## trt1 -0.5876 0.281 27 -1.1644 -0.0107
## trt2 0.6460 0.281 27 0.0692 1.2229
##
## Confidence level used: 0.95emmeans::contrast(emm, method = "pairwise", adjust = "tukey") #pairwiseで条件の組み合わせごとのemmeansの比較の結果が表示される。adjustで多重比較補正の方法を指定できる。## contrast estimate SE df t.ratio p.value
## ctrl - trt1 0.529 0.398 27 1.331 0.3909
## ctrl - trt2 -0.705 0.398 27 -1.772 0.1980
## trt1 - trt2 -1.234 0.398 27 -3.103 0.0120
##
## P value adjustment: tukey method for comparing a family of 3 estimates12.10.2 二要因の分散分析における単純主効果検定
dat = warpbreaks |> dplyr::mutate(breaks_std = scale(breaks))
result = lm(data = dat, breaks_std ~ wool * tension)
emm = emmeans::emmeans(result, ~ wool * tension)
emm## wool tension emmean SE df lower.CL upper.CL
## A L 1.24311 0.276 48 0.688 1.799
## B L 0.00561 0.276 48 -0.550 0.561
## A M -0.31429 0.276 48 -0.870 0.241
## B M 0.04770 0.276 48 -0.508 0.603
## A H -0.27219 0.276 48 -0.828 0.283
## B H -0.70995 0.276 48 -1.265 -0.154
##
## Confidence level used: 0.95## wool = A:
## contrast estimate SE df t.ratio p.value
## L - M 1.5574 0.391 48 3.986 0.0007
## L - H 1.5153 0.391 48 3.878 0.0009
## M - H -0.0421 0.391 48 -0.108 0.9936
##
## wool = B:
## contrast estimate SE df t.ratio p.value
## L - M -0.0421 0.391 48 -0.108 0.9936
## L - H 0.7156 0.391 48 1.831 0.1704
## M - H 0.7577 0.391 48 1.939 0.1389
##
## P value adjustment: tukey method for comparing a family of 3 estimates## tension = L:
## contrast estimate SE df t.ratio p.value
## A - B 1.238 0.391 48 3.167 0.0027
##
## tension = M:
## contrast estimate SE df t.ratio p.value
## A - B -0.362 0.391 48 -0.926 0.3589
##
## tension = H:
## contrast estimate SE df t.ratio p.value
## A - B 0.438 0.391 48 1.120 0.268212.11 補足2(単純傾斜)
本章では2つの変数の積を加えた交互作用のモデルを扱ったが、ここで交互作用を構成する2つの変数について\(X\)を「予測変数」、\(M\)を「調整変数」と区別する。
調整変数(moderating variable):予測変数\(X\)と応答変数\(Y\)との関係を調整する変数
予測変数\(X\)と調整変数\(M\)の積である交互作用を含むモデルでは、予測変数の傾きが意味するのは予測変数そのものの効果ではなく、調整変数がゼロの時に予測変数が1単位変化したときの応答変数の変化量であった。
このような調整変数が特定の値を取るときの予測変数が応答変数に与える効果のことを単純傾斜(simple slope)と表現する。単純傾斜は、交互作用がいかなるかたちで生じているかの解釈に用いられる。
12.11.1 調整変数がカテゴリカル変数,予測変数が量的変数のとき
本章で交互作用の解説で用いたサンプルデータを再び例にして、単純傾斜の推定方法について理解する。
set.seed(1)
#男性のみのデータ
x = round(runif(n = 20, min = 1, max = 10),0)
mu = 0.1 + 0.4 * x
y = rnorm(n = 20, mean = mu, sd = 1)
d_M = data.frame(x = x, y = y, gender = "M")
#女性のみのデータ
x = round(runif(n = 20, min = 1, max = 10),0)
mu = 0.3 + -0.6 * x
y = rnorm(n = 20, mean = mu, sd = 1)
d_F = data.frame(x = x, y = y, gender = "F")
#2つを合わせたデータ
d = rbind(d_M, d_F)
head(d)## x y gender
## 1 3 2.811781 M
## 2 4 2.089843 M
## 3 6 1.878759 M
## 4 9 1.485300 M
## 5 3 2.424931 M
## 6 9 3.655066 M性別を調整変数、\(x\)を予測変数として考える。
本章で行った分析と同様に、男性(gender == M)ならば1,女性(gender == F)ならば0のダミー変数Mを作成し、調整変数Mと予測変数x、さらに2つの積である交互作用(x:M)を加えた線形モデルを実行する。
#ダミー変数の作成
d$M = ifelse(d$gender == "M", 1, 0) #genderがMならば1, Fならば1のダミー変数を作る
result_1 = lm(data = d, y ~ 1 + x*M) #F=0, M=1のダミー変数を使った場合
round(coef(summary(result_1)), 3) #係数を確認する## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.051 0.536 0.095 0.925
## x -0.537 0.081 -6.622 0.000
## M 1.048 0.737 1.421 0.164
## x:M 0.779 0.113 6.907 0.000xの傾きは調整変数Mがゼロのとき、すなわち女性のxの傾き(xが1単位増加したときのyの変化量)を意味していた。
式で表すと、
\[ \hat{y} = \alpha + \beta_{1} x + \beta_{2} M + \beta_{3} xM \\ \]
である。式からも、\(x\)の傾きである\(\beta_{1}\)は、調整変数\(M\)がゼロ(すなわち、女性)のときに\(x\)が1単位増えたときの\(y\)の変化量であることが明らかである。
逆に、男性の時のxの傾きを知りたいときにはどうすればよいか?この場合、先程のダミー変数のコーディングを逆にしたダミー変数を代わりに使えば良い。つまり、「女性ならば1, 男性ならば0」のダミー変数Fを作成し、調整変数F, 予測変数x及び交互作用項x:Fからyを予測する線形モデルを実行してみる。
d$F = ifelse(d$gender == "F", 1, 0) #genderがFならば1, Mならば1のダミー変数を作る
result_2 = lm(data = d, y ~ 1 + x*F) #F=1, M=0のダミー変数を使った場合
round(coef(summary(result_2)), 3) #係数を確認する## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.099 0.506 2.171 0.037
## x 0.242 0.078 3.086 0.004
## F -1.048 0.737 -1.421 0.164
## x:F -0.779 0.113 -6.907 0.000このxの傾きが、調整変数Fがゼロのとき、すなわち男性のxの傾きを意味する。
式で表すと、
\[ \hat{y} = \alpha + \beta_{1} x + \beta_{2} F + \beta_{3} xF \\ \]
である。
このように、ダミー変数のコーディングを工夫することで、それぞれの調整変数別に予測変数と応答変数との関連(単純傾斜)を推定することができる。
interactionsパッケージのsim_slopew関数を使えば、ダミー変数を作り直さなくても調整変数のカテゴリごとに単純傾斜を算出することができる。
library(interactions)
interactions::sim_slopes(result_1, pred = x, modx = M) #predに予測変数、modxに調整変数を入れる。## JOHNSON-NEYMAN INTERVAL
##
## When M is OUTSIDE the interval [0.54, 0.87], the slope of x is p < .05.
##
## Note: The range of observed values of M is [0.00, 1.00]
##
## SIMPLE SLOPES ANALYSIS
##
## Slope of x when M = 0.00 (0):
##
## Est. S.E. t val. p
## ------- ------ -------- ------
## -0.54 0.08 -6.62 0.00
##
## Slope of x when M = 1.00 (1):
##
## Est. S.E. t val. p
## ------ ------ -------- ------
## 0.24 0.08 3.09 0.00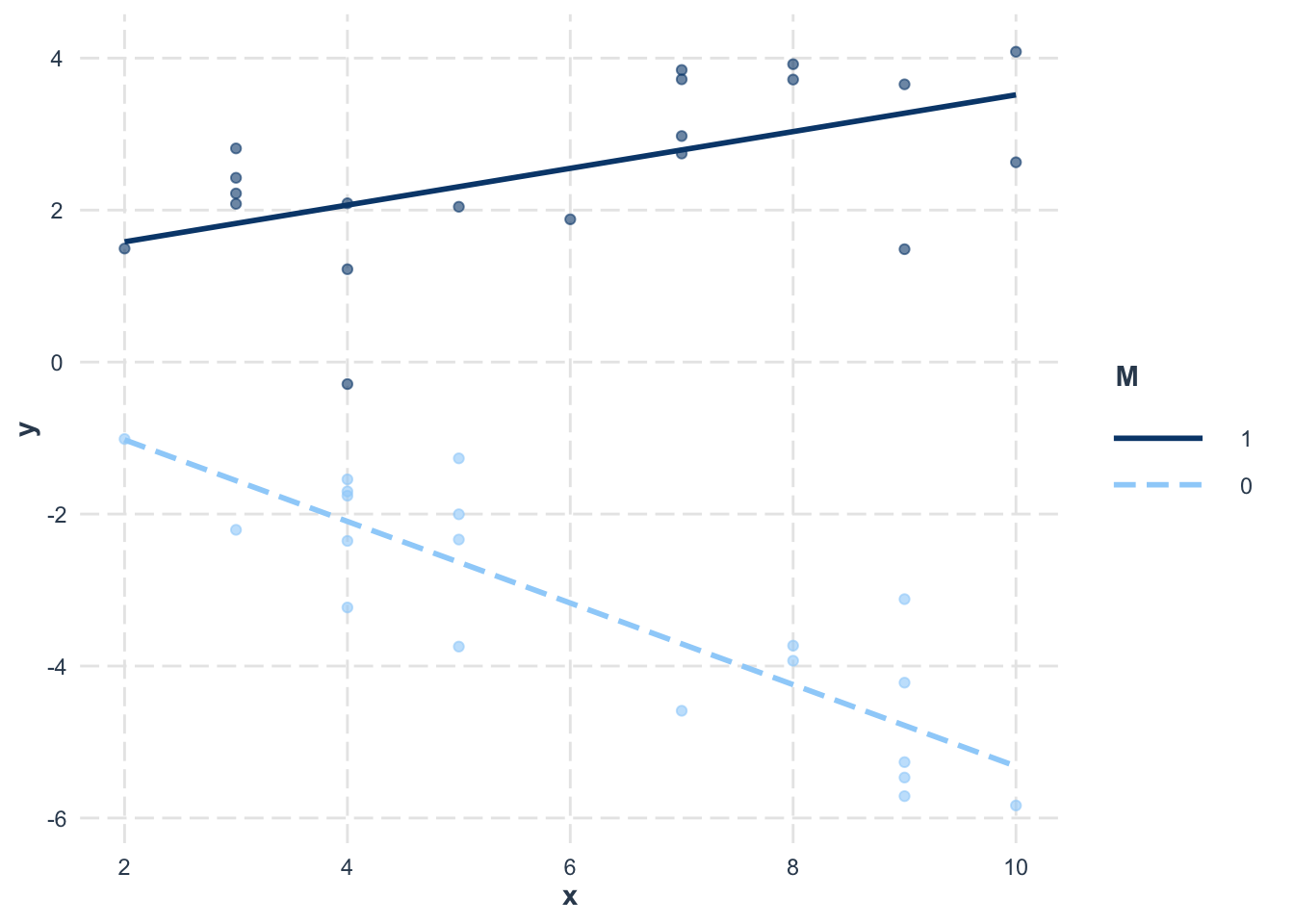
また、emmeansパッケージのemtrendsでも同様に推定することができる。
## M x.trend SE df lower.CL upper.CL
## 0 -0.537 0.0811 36 -0.7013 -0.372
## 1 0.242 0.0783 36 0.0829 0.401
##
## Confidence level used: 0.95それぞれで推定された結果が、先ほどの線形モデルでの\(x\)の傾きの推定値と一致していることがわかる。
また、emtrendsでは単純傾斜の比較もすることができる(男性と女性で傾きが有意に異なるか?)。この結果は、線形モデルの推定結果に表示される交互作用項の検定の結果と一致する(交互作用の傾きが意味するのは「調整変数が1であるときに、予測変数の傾きがどのくらい変化するか」であり、その増え方がゼロより有意に大きいあるいは小さいかを検定している)。
## $emtrends
## M x.trend SE df lower.CL upper.CL
## 0 -0.537 0.0811 36 -0.7013 -0.372
## 1 0.242 0.0783 36 0.0829 0.401
##
## Confidence level used: 0.95
##
## $contrasts
## contrast estimate SE df t.ratio p.value
## M0 - M1 -0.779 0.113 36 -6.907 <0.0001## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.051 0.536 0.095 0.925
## x -0.537 0.081 -6.622 0.000
## M 1.048 0.737 1.421 0.164
## x:M 0.779 0.113 6.907 0.000なお、上述の例は、調整変数がカテゴリカル変数で予測変数が量的変数の場合だが、両者ともカテゴリカル変数の場合でも解釈は同様である(予測変数の傾きは、調整変数がゼロのときの予測変数がゼロから1に変化したときの応答変数の変化量)。
12.11.2 予測変数と調整変数が量的変数のとき
交互作用項が2つの量的変数の積である場合も、予測変数の傾きが意味することは「調整変数がゼロであるときの予測変数の傾き」という点で同じだが、モデルによっては解釈に注意が必要である。
サンプルデータの解析を通して確認していく。
#サンプルデータの作成
set.seed(1)
m = rnorm(n = 40, mean = 1, sd = 1)
x = rnorm(n = 40, mean = 2, sd = 1)
mu = 0.1 + 0.3 * x + 0.2 * m - 0.2 * x * m
y = rnorm(n = 40, mean = mu, sd = 1)
d = data.frame(x = x, m = m, y = y)
head(d)## x m y
## 1 1.835476 0.3735462 0.01955638
## 2 1.746638 1.1836433 0.31206219
## 3 2.696963 0.1643714 2.03138956
## 4 2.556663 2.5952808 -1.46456346
## 5 1.311244 1.3295078 1.00455913
## 6 1.292505 0.1795316 0.81019905mを調整変数、xを予測変数とし、応答変数yを予測する線形モデルを行う。
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.104 0.473 -0.220 0.827
## x 0.615 0.229 2.690 0.011
## m 0.024 0.368 0.066 0.947
## x:m -0.262 0.165 -1.592 0.120モデルを式で表すと、以下の通りになる。
\[ \hat{y} = \alpha + \beta_{1} x + \beta_{2} m + \beta_{3} x m \\ \]
先ほどと同様に\(\beta_{1}\)は\(m = 0\)であるときの\(x\)が1単位増えたときの\(y\)の変化量として解釈することができる。
しかし、調整変数がゼロを取り得ない変数である場合には(例として身長や体重など)、係数の意味の解釈がしにくくなる(本章でも述べているように、平均値をゼロに変換する標準化も一つの対応策である)。
そこで、調整変数が量的変数の場合には調整変数のレベルを「平均」、「平均+1標準偏差」および「平均 - 1標準偏差」の3つに分けて、予測変数の単純傾斜を推定することが多い。
ここでは、mが「平均」、「平均 + 1標準偏差」および「平均 - 1標準偏差」の場合に分けて、xがyに及ぼす影響を見てみよう。
d$m_minus_SD = d$m - (mean(d$m) - sd(d$m)) # mが平均-1標準偏差の値であるときにゼロになる変数を作成
d$m_plus_SD = d$m - (mean(d$m) + sd(d$m)) # mが平均値であるときにゼロになる変数を作成
d$m_mean = d$m - mean(d$m) # mが平均+1標準偏差の値であるときにゼロになる変数を作成
round(coef(summary(lm(data = d, y ~ 1 + x * m_minus_SD))), 3) # mean -1SD## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.099 0.423 -0.234 0.816
## x 0.561 0.204 2.753 0.009
## m_minus_SD 0.024 0.368 0.066 0.947
## x:m_minus_SD -0.262 0.165 -1.592 0.120## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.077 0.339 -0.228 0.821
## x 0.329 0.147 2.241 0.031
## m_mean 0.024 0.368 0.066 0.947
## x:m_mean -0.262 0.165 -1.592 0.120## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.056 0.514 -0.108 0.915
## x 0.096 0.210 0.459 0.649
## m_plus_SD 0.024 0.368 0.066 0.947
## x:m_plus_SD -0.262 0.165 -1.592 0.120それぞれのモデルのxの傾きは、m_minum_SD, m_mean, m_plus_SDがゼロのとき、すなわち調整変数がそれぞれ平均-1標準偏差, 平均、平均-1標準偏差の値を取るときのxの傾きを意味する。
「平均」、「平均+1標準偏差」、「平均-1標準偏差」に対応する変数を新たに作らなくても、interactionsパッケージのsim_slopesでも単純傾斜を推定することができる。
## JOHNSON-NEYMAN INTERVAL
##
## When m is INSIDE the interval [-3.18, 1.20], the slope of x is p < .05.
##
## Note: The range of observed values of m is [-1.21, 2.60]
##
## SIMPLE SLOPES ANALYSIS
##
## Slope of x when m = 0.2053592 (- 1 SD):
##
## Est. S.E. t val. p
## ------ ------ -------- ------
## 0.56 0.20 2.75 0.01
##
## Slope of x when m = 1.0920262 (Mean):
##
## Est. S.E. t val. p
## ------ ------ -------- ------
## 0.33 0.15 2.24 0.03
##
## Slope of x when m = 1.9786932 (+ 1 SD):
##
## Est. S.E. t val. p
## ------ ------ -------- ------
## 0.10 0.21 0.46 0.65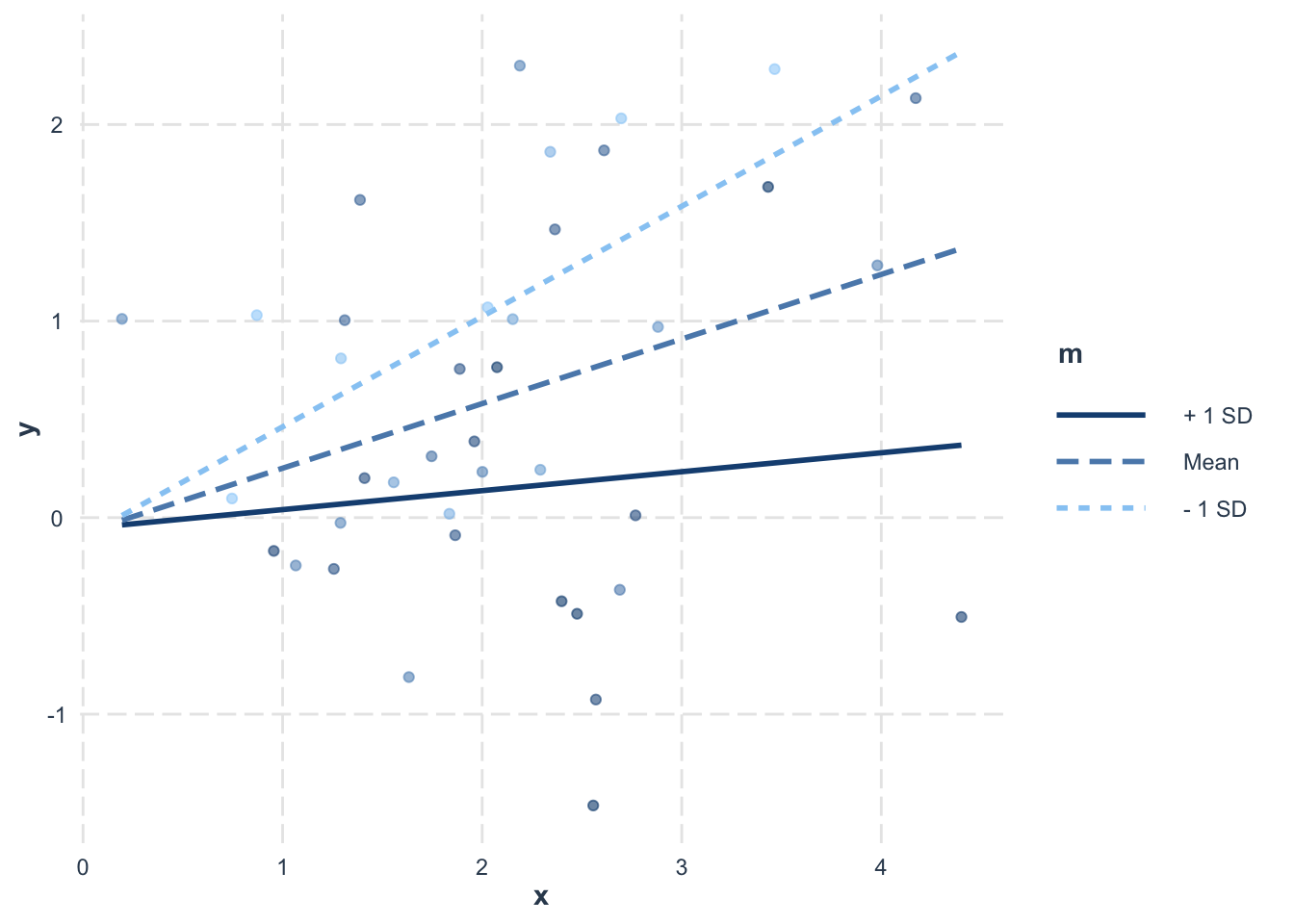
#emmeansパッケージのemtrendsを使う場合(自分でmean -1sd, mean, mean + 1sdのレベルを予め指定する必要がある)
m_minus_SD = (mean(d$m) - sd(d$m)) # m = mean - 1SDのときにゼロになる変数を作成
m_Mean = mean(d$m) # m = mean のときにゼロになる変数を作成
m_plus_SD = (mean(d$m) + sd(d$m)) # m = mean + 1SDのときにゼロになる変数を作成
m_list = list(m = c(m_minus_SD, m_plus_SD, m_Mean))
emmeans::emtrends(result_3, specs = "m", var = "x", at = m_list)## m x.trend SE df lower.CL upper.CL
## 0.205 0.5610 0.204 36 0.1476 0.974
## 1.979 0.0964 0.210 36 -0.3296 0.522
## 1.092 0.3287 0.147 36 0.0312 0.626
##
## Confidence level used: 0.95## $emtrends
## m x.trend SE df lower.CL upper.CL
## 0.205 0.5610 0.204 36 0.1476 0.974
## 1.979 0.0964 0.210 36 -0.3296 0.522
## 1.092 0.3287 0.147 36 0.0312 0.626
##
## Confidence level used: 0.95
##
## $contrasts
## contrast estimate SE df t.ratio p.value
## m0.20535917754117 - m1.97869318000282 0.465 0.292 36 1.592 0.2623
## m0.20535917754117 - m1.092026178772 0.232 0.146 36 1.592 0.2623
## m1.97869318000282 - m1.092026178772 -0.232 0.146 36 -1.592 0.2623
##
## P value adjustment: tukey method for comparing a family of 3 estimates