Chapter 3 データ
Rでデータ分析を行う前に、Rでのデータの使い方を理解する。
- プログラミングの練習
- 変数
- Rのデータ構造(ベクトル、データフレーム、tibble)
- 欠損値
- 外部データの読み込み(csv, xlsx, その他SPSSやStataのファイルなど)
- データの書き出し
- サンプルデータ
3.1 はじめに(パッケージのロード)
この章ではtibble,readr,havenといったパッケージを使うので、あらかじめロードをしておく(未インストールの場合はインストールする必要あり。パッケージのインストール方法については第2章を参照のこと)。
注意:
以降のプログラムでは、パッケージに入っている関数を呼び出す際に「XXXX::YYYY」というかたちでプログラムを書いている。
これらは「XXXXパッケージに入っているYYYYという名前の関数を使う」ということを意味している。XXXX::の部分は基本的に省略しても問題ないが、例えば複数のパッケージをロードしていて、同じ名前の関数が別のパッケージに含まれている場合には、思った通りの結果が表示されない場合もある。外部パッケージの関数を使う場合は、できる限りXXXX::を付けてどのパッケージの関数を使うのかを明示して使うのが良い。
3.2 プログラミングの練習
ここでは、Rで使える識別子(operator)の解説を通して、プログラミングの練習を行う。
3.4 変数の型
R では変数の種類として、数値型、文字列、日付、論理型の区別をする。
a = 1
b = "1"
c = as.Date("2020-06-15")
d = TRUE
#class()でその変数の型を確認することができる
class(a)
class(b)
class(c)
class(d) 3.4.1 数値型(numeric)
数値型として格納した変数は、数値として扱うことができる。数値型の変数同士で、演算(足し算・引き算・掛け算・割り算)を行うことができる。
## [1] 6.2数値型には、整数型(integer)と浮動小数点型(double)の区別もある(データ分析においては意識して区別することはあまりない)。
## [1] 1## [1] 1.53.4.2 文字列(character)
文字として扱われる。文字列同士は演算をすることができない。
文字を変数として代入したい場合は、文字をクオテーションマーク""で囲む。
## [1] "hello"## [1] "1"同じ文字でも、因子型(factor)というものもある。因子型には順序情報を付与することができる。グラフで軸がカテゴリの場合で順序を並び替えたいときや、順序変数を用いた分析の際に活用することがある。
x = c("Good", "Very Bad", "Moderate", "Very Good", "Bad")
factor(x, ordered = TRUE, levels = c("Very Bad", "Bad", "Moderate", "Good", "Very Good"))## [1] Good Very Bad Moderate Very Good Bad
## Levels: Very Bad < Bad < Moderate < Good < Very Good3.5 データ構造
複数の数値や文字列などをまとめた構造を、データと呼ぶ。R には、データを扱うための形式がいくつか用意されている。
3.5.1 ベクトル
同じ型の要素を集めたものであり、最も単純なデータ型である。c()関数で、ベクトルを作成することができる。
## [1] 1 2 3 4 5## [1] "a" "b" "c" "d" "e"ベクトル[x]の表記でカッコの中に数値を入れると、そのベクトルの x 番目の要素を取り出せる。
## [1] 2## [1] "c"カッコの中に条件式を入れると、その条件に当てはまる要素を取り出せる。
## [1] 3 4 5## [1] "c"## [1] "a" "b" "d" "e"ベクトルが数値で構成されている場合は、演算をすることもできる。
## [1] 2 4 6 8 10## [1] 7 9 11 13 153.5.2 データフレーム
複数のベクトルを行列でまとめたデータ構造を、R ではデータフレームと呼ぶ。データフレームは頻繁に使うので、構造を覚えよう。
2つのベクトルを作成し、この2つのベクトルからなるデータフレームを作成する。data.frame()は、データフレームを作るための関数である。
x_vec = c(1, 2, 3, 4, 5)
y_vec = c("a", "b", "c", "d", "e")
dat = data.frame(x = x_vec, y = y_vec)
dat## x y
## 1 1 a
## 2 2 b
## 3 3 c
## 4 4 d
## 5 5 eデータフレームでの変数の使い方
以下のように、データフレーム$変数名で、データフレームの変数をベクトルとして取り出すができる。
## [1] 1 2 3 4 5データフレームに新たに変数を加えることも出来る。
## x y x_2
## 1 1 a 6
## 2 2 b 7
## 3 3 c 8
## 4 4 d 9
## 5 5 e 10## x y x_2 x_3
## 1 1 a 6 7
## 2 2 b 7 9
## 3 3 c 8 11
## 4 4 d 9 13
## 5 5 e 10 15データフレーム$変数名でデータ内の変数にアクセスする方法は、今後もよく使うので覚えておこう。
データの抽出
データフレーム[行数,列数]のかたちで指定することで、データフレームの行列を取り出すことができる。
## [1] "a"## x y x_2 x_3
## 1 1 a 6 7## [1] 1 2 3 4 5## x y x_2 x_3
## 1 1 a 6 7
## 2 2 b 7 9
## 3 3 c 8 11## x y x_2 x_3
## 1 1 a 6 7
## 3 3 c 8 11
## 5 5 e 10 15カッコ内に条件式を入れると、その条件と一致する部分を取り出せる。
## x y x_2 x_3
## 3 3 c 8 11
## 4 4 d 9 13
## 5 5 e 10 15## x y x_2 x_3
## 4 4 d 9 13
## 5 5 e 10 153.5.3 tibble
更に、Rにはデータフレームの可読性を向上させたtibbleというデータ形式が用意されている。tibble形式のデータを扱うには、tibbleパッケージが必要となる。
as_tibble()でデータフレームをtibble形式にすることができる。Rにあらかじめ入っているサンプルデータirisを試しにtibble型にしてみよう。
## # A tibble: 150 × 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ℹ 140 more rowstibble形式のデータは、コンソールにデータ全てではなく最初の10行程度のみが表示される。列も画面に入る範囲のみが表示される。データの行数と列数、データの変数の型なども表示される。
tibbleだとデータをすべて閲覧することはできないが、すべて閲覧したい場合はView()を使えばよい。別ウィンドウが開いて、データを閲覧することができる。
3.6 欠損値
Rでは、欠損値(データが空の部分)はNAで扱う。
先程の例で作ったデータフレームdatに、欠損値を含む変数x_4を入れてみよう。
## x y x_2 x_3 x_4
## 1 1 a 6 7 1
## 2 2 b 7 9 2
## 3 3 c 8 11 NA
## 4 4 d 9 13 4
## 5 5 e 10 15 5## [1] 2 4 NA 8 10欠損値を含むベクトルは、計算に用いることができない。例えば、R には平均値を計算するためのmean()という関数がある。しかし、欠損値を含むベクトルの場合は結果が出力されない。
## [1] NA関数によっては、欠損値を含むデータを使うときには欠損値の処理を指定する必要がある。例えば、mean()ならば、オプションとしてna.rm =TRUEを入れると欠損値を除いた上で平均値を計算してくれる。
## [1] 33.7 データの読み込み
上述の例では自分でプログラムを書いてデータフレーム等を作成したが、大抵の場合はデータを ファイルなどに保存したデータを読み込んで使うことが多い。以下では、RでCSVやExcelファイルなどを読み込む方法を確認していく。
3.7.1 ワーキングディレクトリの設定
データを読み込む前に、ワーキングディレクトリ (Working directory)について理解する必要がある。ワーキングディレクトリとは、「現在居る場所」のことである。ファイルを読み込む際には、Rにデータがどこに有るかを教える必要がある。Rはワーキングディレクトリを起点にして、読み込むファイルを探す。
試しに、現在のワーキングディレクトリを確認しよう。以下のプログラムをコンソールに入力して実行する。
出力された場所が、現在のワーキングディレクトリである。
読み込みたいファイルをデスクトップに保存してある場合を例として理解していこう。すなわち、デスクトップをワーキングディレクトリとして指定する必要がある。
ワーキングディレクトリをデスクトップに変更するには、以下のプログラムを書き込んで実行する。
3.7.2 外部ファイルの読み込み
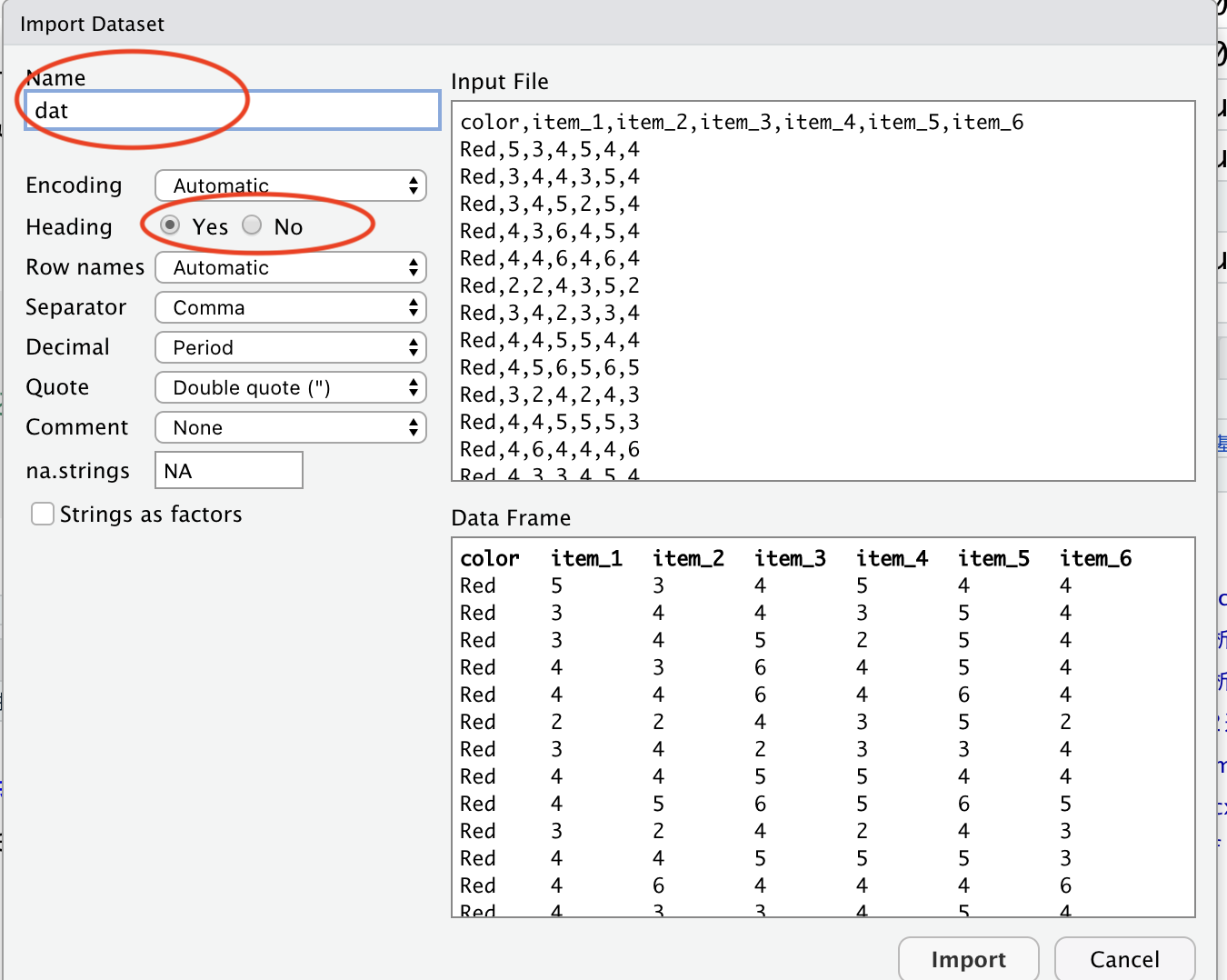
csvファイルの読み込み
read.csv()関数で読み込むことが出来る。
また、readrパッケージのread_csv()関数でもcsvファイルを読み込むことができる。更に、読み込まれたデータはtibble型になる。
read.csv()ではなく、read_csv()なので注意(ドットではなく、アンダースコア)。
Excelファイルの読み込み
readxlパッケージのread_excel()で、xlsx形式のデータも読み込むことができる。
特にオプションを指定しなければ、1番目に保存されているシートの中身をtibble形式で読み込んでくれる。読み込みたいシートや読み込む範囲を指定したい場合など、細かい点についてはread_excelのヘルプを参照のこと。
相対パス
上記の例では、デスクトップ上に読み込みたいファイルを保存し、デスクトップをワーキングディレクトリに指定してデータを読み込んだ。しかし、例えばデスクトップにあるフォルダの中にデータを保存してあってそのファイルを読み込みたい場合、いちいちワーキングディレクトリを設定し直すのは面倒である。
このような場合、相対パスでファイルを指定するのが便利である。
#デスクトップをワーキングディレクトリに指定する
##Windowsの場合
setwd("C:/Users/ユーザー名/Desktop") #ユーザー名には設定しているアカウント名を入れる。
##Macの場合
setwd("~/Desktop")
#デスクトップにあるDataフォルダの中の「0_sample.csv」を読み込む
dat = read.csv("./Data/0_sample.csv").(ピリオド)は、ワーキングディレクトリを意味する。/(スラッシュ)でフォルダの階層を区切ることで、下の層のフォルダにアクセスすることができる。